Multiple header cells in a table support identification
A table's header cells are in charge of making the corresponding data cells distinguishable, so users can easily identify data cells and navigate through the table flawlessly. But sometimes it is hard to find the correct cells that fit in this respect, so you can try to introduce another one - or to use a combination of cells.
Ambiguous data
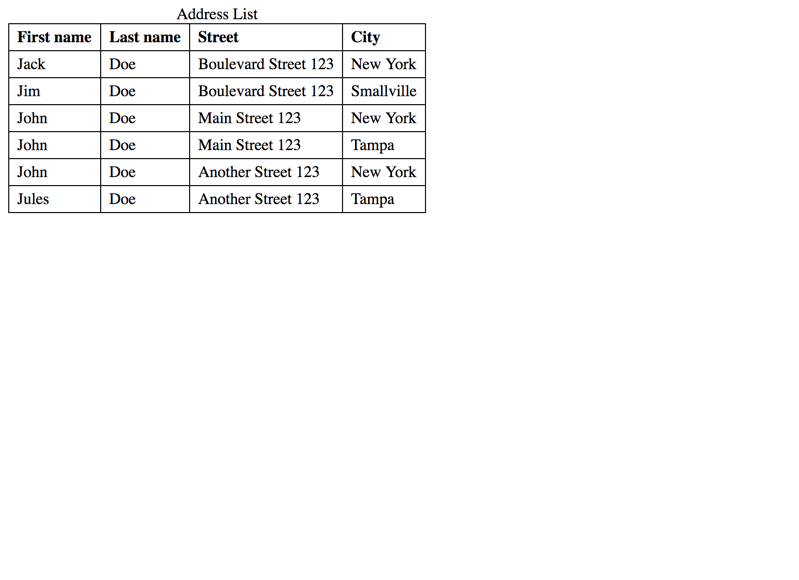
Sometimes a data table does not offer a column that identifies the current row (so it could be used as the <th> element).
For example, when having a huge database of addresses, chances are high that you have multiple records with very similar data, as demonstrated in the following example: here you have many John Does residing on similar addresses.
<table><caption>Address List</caption><thead><tr><th>
First name
</th><th>
Last name
</th><th>
Street
</th><th>
City
</th></tr></thead><tbody><tr><td>
Jack
</td><td>
Doe
</td><td>
Boulevard Street 123
</td><td>
New York
</td></tr><tr><td>
Jim
</td><td>
Doe
</td><td>
Boulevard Street 123
</td><td>
Smallville
</td></tr><tr><td>
John
</td><td>
Doe
</td><td>
Main Street 123
</td><td>
New York
</td></tr><tr><td>
John
</td><td>
Doe
</td><td>
Main Street 123
</td><td>
Tampa
</td></tr><tr><td>
John
</td><td>
Doe
</td><td>
Another Street 123
</td><td>
New York
</td></tr><tr><td>
Jules
</td><td>
Doe
</td><td>
Another Street 123
</td><td>
Tampa
</td></tr></tbody></table>
<table><caption>Address List</caption><thead><tr><th>
ID
</th><th>
First name
</th><th>
Last name
</th><th>
Street
</th><th>
City
</th></tr></thead><tbody><tr><th>
1000001
</th><td>
Jack
</td><td>
Doe
</td><td>
Boulevard Street 123
</td><td>
New York
</td></tr><tr><th>
1000002
</th><td>
Jim
</td><td>
Doe
</td><td>
Boulevard Street 123
</td><td>
Smallville
</td></tr><tr><th>
1000003
</th><td>
John
</td><td>
Doe
</td><td>
Main Street 123
</td><td>
New York
</td></tr><tr><th>
1000004
</th><td>
John
</td><td>
Doe
</td><td>
Main Street 123
</td><td>
Tampa
</td></tr><tr><th>
1000005
</th><td>
John
</td><td>
Doe
</td><td>
Another Street 123
</td><td>
New York
</td></tr><tr><th>
1000006
</th><td>
Jules
</td><td>
Doe
</td><td>
Another Street 123
</td><td>
Tampa
</td></tr></tbody></table>
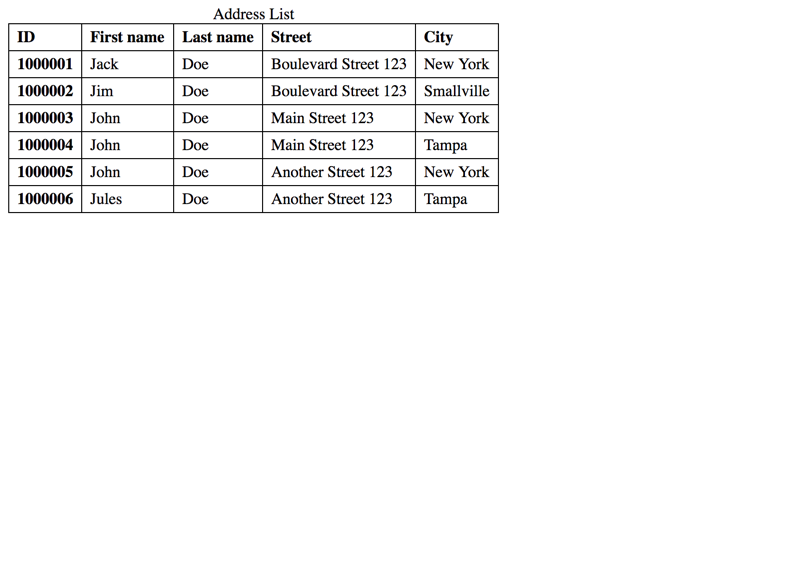
However, record IDs are often not very readable. And sometimes there is not even a record ID available.
Marking multiple cells as headers
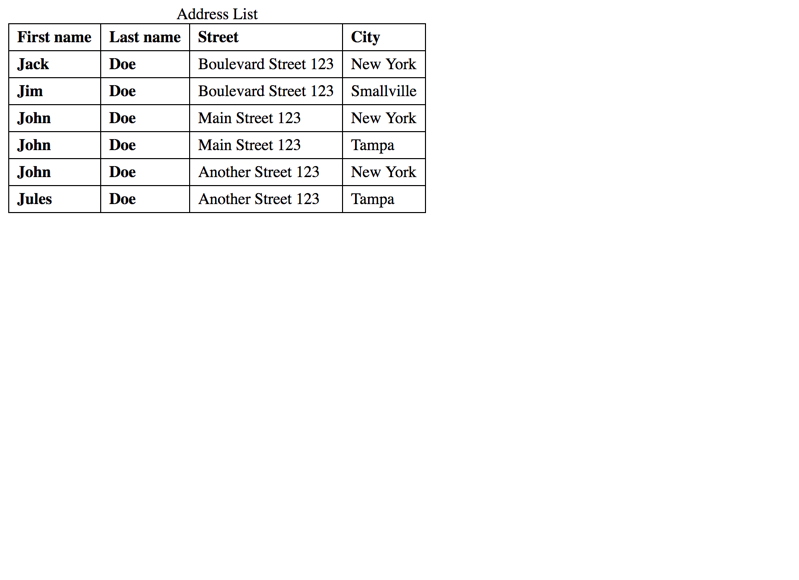
Thus, sometimes it is best to mark more than a single data cell as header cell. Then, the combination of the header cells is announced by the screen reader, identifying the current row as uniquely as possible.
<table><caption>Address List</caption><thead><tr><th>
First name
</th><th>
Last name
</th><th>
Street
</th><th>
City
</th></tr></thead><tbody><tr><th>
Jack
</th><th>
Doe
</th><td>
Boulevard Street 123
</td><td>
New York
</td></tr><tr><th>
Jim
</th><th>
Doe
</th><td>
Boulevard Street 123
</td><td>
Smallville
</td></tr><tr><th>
John
</th><th>
Doe
</th><td>
Main Street 123
</td><td>
New York
</td></tr><tr><th>
John
</th><th>
Doe
</th><td>
Main Street 123
</td><td>
Tampa
</td></tr><tr><th>
John
</th><th>
Doe
</th><td>
Another Street 123
</td><td>
New York
</td></tr><tr><th>
Jules
</th><th>
Doe
</th><td>
Another Street 123
</td><td>
Tampa
</td></tr></tbody></table>
As you see in the example above, the combinations of first and last names still aren't unique. So you could add even more cells as header cells…
But please do not overdo this. You usually should never need more than two or maybe three header cells for a row, even if they are not fully identifying each and every record. This is better than having all of the cells marked up as header cells (which would be absurd).